
LLM(Large Language Models) : 대규모 언어를 다루는 모델
LLM에 대한 GPT의 대답 : 방대한 양의 데이터로부터 언어와 유사한 텍스트를 이해하고 만들어내는 기술
모든 인간의 언어, 기계어 등 언어들을 처리하는 것이 Language Model(언어 처리) 이고 그 언어들을 처리할 때 방대한 양의 학습 데이터를 사용했다 혹은 꽤나 많은 양의 리소스를 사용한다 하면 Large Language Models 이 됨
LLM의 task
번역, 오타 수정, 물어보면 거기에 대한 답을 한다든지, 요약, 그냥 일반적인 대화 생성
NLP와 LLM의 차이?
LLM은 NLP(Natural Language Processing)의 한 분야이자 매우 큰 데이터 set만 씀 ( 이 차이만 있다)
LLM 작동 방식 및 원리
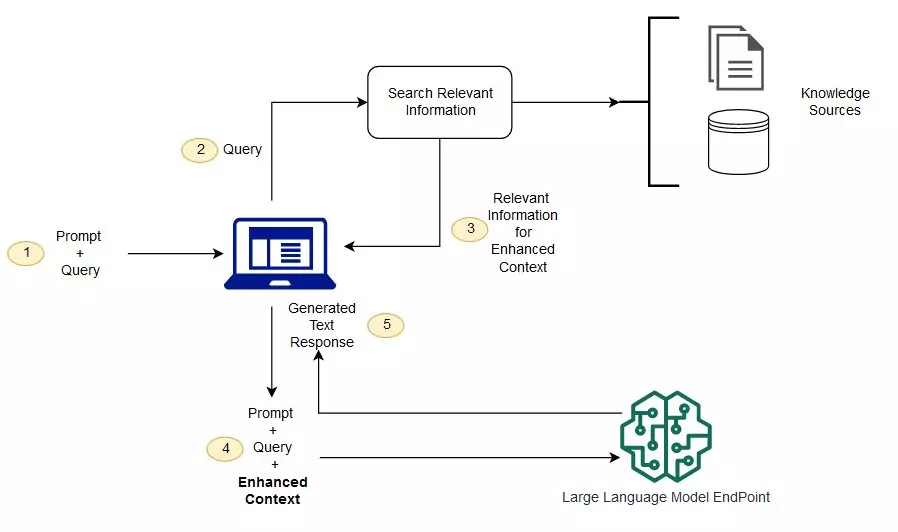
LLM(Large Language Model)에서 어떤 언어 모델을 학습을 할 것임
언어 모델 학습 시에 주로 인터넷에 있는 소스들을 많이 사용
실제로 ChatGPT가 학습을 할 때 사용한 리소스들이 인터넷에 있는 문서들 대화들 다 끌어모아서 그 구조를 학습한 것임(그림에서 Knowledge Sources에 해당)
Knowledge sources 는 그런 방대한 언어를 의미
1. Prompt + Query : ChatGPT라고 가정. 여기서 질문 입력
그런 질문들에 입력을 하면
3. Relevant Information for Enhanced Context : 이 과정과 Large Language Model을 거쳐서
5. Generated Text Response에서처럼 대답을 내놓는다
위의 사진과 같이 이루어지는 것도 있고 그냥 뉴럴 네트워크 모델을 통과해서 즉각적으로 대답을 내놓는 경우도 있다
우리가 질문을 하면 여기에 대한 대답을 LLM에서 내놓아야 한다
그 내놓은 과정을 어떻게 처리하는지 한번 보자
LLM의 언어 처리 과정
그림 1) Transformer 구조
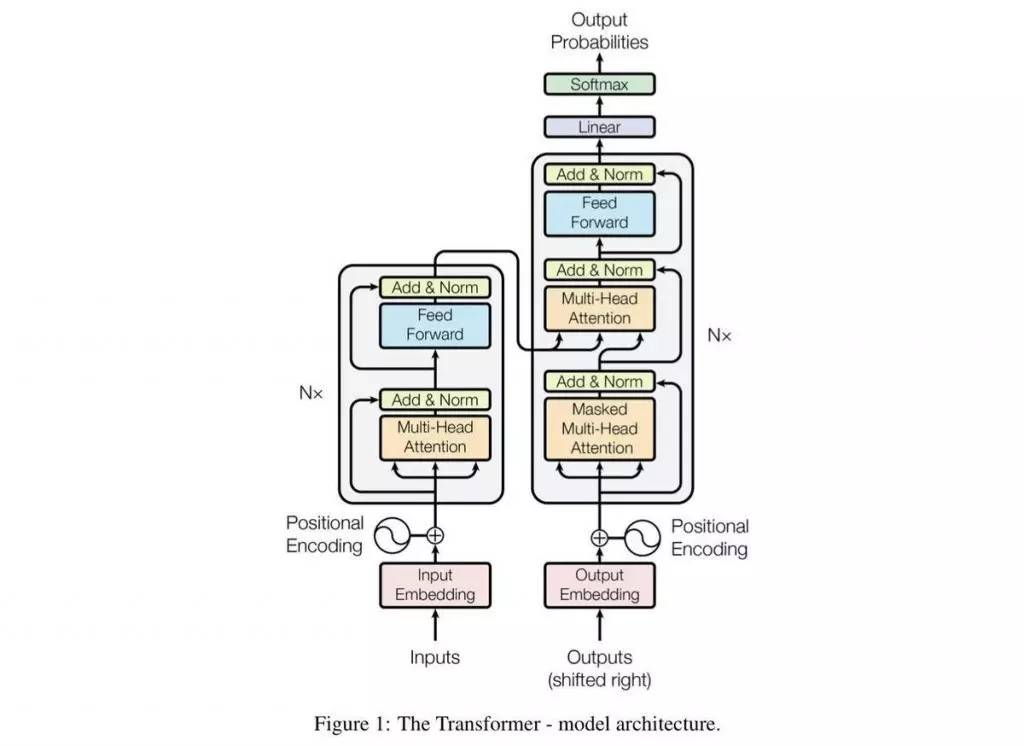
그림1은 트랜스포머 구조이고 input과 output layer로 구성이 되어있다
input : 질문의 영역
input에서는 질문하는 거 GPT한테 무슨 질문을 한다면 그러한 것들이 다 input에 들어감
output: 대답을 생성하는
그것이 output단으로 넘어가서 output단에서는 대답을 생성
여기서 중요한 것이 그림2에 있는 Self-Attention이라는 것
그림 2) Self-Attention

기본적인 딥러닝 모델, 예를 들어서 이미지를 분류한다든지 글씨가 어떤 글자인지를 분류한다든지 이런 분류 모델은 데이터 자체에 특징만 뽑아내면 됐었다
분류 모델 = 데이터의 특징만 해당
그런데 언어 같은 경우는 결국에는 시간에 따라서 계속해서 내가 어떠한 소리를 말을 하고 있는 것이다
근데 그 말을 하고 있는 것이 인과 관계가 있다
예를 들어서
한국어 : 주어 다음에 목적어 다음에 동사
영어 : 주어 + 동사 + 목적어 이런 순으로 어순이라는 것이 있고
그리고 그 문장이 모여서 문단을 형성할 때 문장과 문장 사이에도 어떠한 관계가 있다
그러한 관계들을 Self-Attention이라는 구조에서 찾을 수 있다
같은 문장 한 문장 내에서 단어와 단어 사이의 연관 관계 혹은 상관관계를 보는 것이다
그래서 그림2에서 보듯이
왼쪽 단어들 사이에서 오른쪽에 위치 it이 가리키는 것이 animal이다
그래서 animal과 it, 이 두개의 연관성이 높다고 하고 animal이라는 걸 분석을 할 때 자기 문장에 있는 다른 단어인 it에 조금 더 가중치를 두는 것이다
이런 식으로 언어의 구조에 대한 이해, 어떻게 하면 조금 더 자연스럽게 말을 할 수 있는지를 컴퓨터가 학습을 하게 되는 것임
데이터 셋 같은 경우 인터넷에서 있는 방대한 양의 텍스트 데이터를 모은다고 했다
논문 같은 전문적인 것부터 그냥 일반적인 인터넷 댓글처럼 조금 문법이 틀릴 수도 있는 혹은 어순이 안 맞을 수도 있는 그런 데이터까지 다 포함
결국에는 언어에 대한 구조를 배울 뿐만 아니라 널리 알려진 지식까지도 다 알아서 습득을 할 수 있는 것임
그리고 지식들을 습득할 때 Word Embedding을 사용
Word Embedding이란?
결국에는 이런 단어와 단어들이 컴퓨터가 이해하려면 숫자로 변환이 되어야 한다
숫자로 변환을 할 때 조금 더 연관성이 높은 단어들은 유사한 숫자들끼리 묶이는 것임(연관성이 높은 단어를 그룹화)
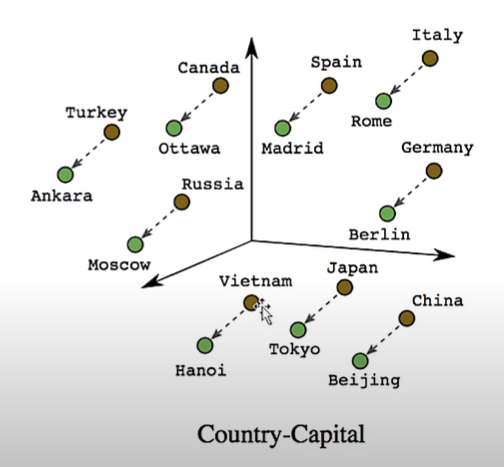
위의 그림을 보면 수도와 국가가 짝지어져 있다
이것들을 다 하나의 숫자로 할당을 한다고 생각을 할 때
같은 국가와 도시의 묶음들은 같은 숫자로, 비슷한 거리에 있는 숫자들로 묶인다는 것임
이것이 Word Embedding의 원리
그림2처럼 Self-Attention을 활용한 이런 기본적인 언어 모델을 사용하면 비슷한 것들은 비슷한 숫자로 매핑이 된다는 것을 확인할 수 있다
그래서 이것이 Word Embedding의 특징이고 그래서 결국에는 어떤 특정한 태스크 즉 손글씨 분류 혹은 예측 같은 특정한 태스크를 목적으로 학습을 하는 것이 아니라 언어 모델 자체의 것을 학습하기 때문에 굉장히 일반화되어 있다
예를 들어서 분류 문제라든지 혹은 내가 어떤 텍스트를 넣었을 때 이 텍스트가 부정적인 감정을 담고 있는지 긍정적인 감정을 담고 있는지 그러한 특정한 문제를 풀고 싶을 때는 LLM을 갖고 와서 거기서 파인튜닝, 즉 우리들이 가지고 있는 데이터로 조금 더 학습을 시키는 것이다
LLM 자체가 이런 파인튜닝을 할 수 있도록 잘 설계가 되어 있다
ChatGPT 같은 경우도 사실은 GPT3 GPT4라는 사전 학습 모델에서 맞춤형으로 발전이 된 것임
그래서 이렇게 파인튜닝해서 사용할 수 있다는 것이다
LLM에서 해결해야 할 문제
LLM은 인터넷에 있는 방대한 양의 자료를 가져와서 학습을 한다
지식도 학습을 한다고 할 수 있는데 Hate speeches라고 혐오,증 발언 등에 노출 위험
그럼 이런 것들이 다 학습이 되고 사람들이 가짜 뉴스 생성, 갈등 유발 정도를 다 걸러내야 한다
이런 문제점들을 해결하는 것이 지금 LLM 모델에서 사람들이 연구하고 있는 분야들 중에 하나
또한 LLM은 gpt를 포함해서 굉장히 모델 자체가 크다(굉장히 무겁게 설계된 LLM)
결국에는 그 모델을 저장하고 관리하기 위해서 전기세가 많이 나감(유지비용 많이 든다)
그래서 이런 리소스 관리 같은 것도 LLM의 주요 과제
인터넷에는 영어 스페인어 이런 것들이 많고 한국어 같은 경우는 비교적 적다
그렇기 때문에 ChatGPT에도 한국어를 입력하면 생성 속도가 좀 느림
아직까지도 LLM 모델에서는 데이터가 적은 한국어는 비주류에 속하기 때문에 그런 비주류 언어에 대해서도 개발을 하려는 것이 많은 기업들과 연구소에서 하고 있는 것
'기업 프로젝트' 카테고리의 다른 글
| [AWS] 윈도우10에서 pem 파일 사용해 aws ec2 접속 (ssh) (0) | 2023.10.17 |
|---|---|
| 마이너 멘토링 10/12 (0) | 2023.10.12 |
LLM(Large Language Models) : 대규모 언어를 다루는 모델
LLM에 대한 GPT의 대답 : 방대한 양의 데이터로부터 언어와 유사한 텍스트를 이해하고 만들어내는 기술
모든 인간의 언어, 기계어 등 언어들을 처리하는 것이 Language Model(언어 처리) 이고 그 언어들을 처리할 때 방대한 양의 학습 데이터를 사용했다 혹은 꽤나 많은 양의 리소스를 사용한다 하면 Large Language Models 이 됨
LLM의 task
번역, 오타 수정, 물어보면 거기에 대한 답을 한다든지, 요약, 그냥 일반적인 대화 생성
NLP와 LLM의 차이?
LLM은 NLP(Natural Language Processing)의 한 분야이자 매우 큰 데이터 set만 씀 ( 이 차이만 있다)
LLM 작동 방식 및 원리
LLM(Large Language Model)에서 어떤 언어 모델을 학습을 할 것임
언어 모델 학습 시에 주로 인터넷에 있는 소스들을 많이 사용
실제로 ChatGPT가 학습을 할 때 사용한 리소스들이 인터넷에 있는 문서들 대화들 다 끌어모아서 그 구조를 학습한 것임(그림에서 Knowledge Sources에 해당)
Knowledge sources 는 그런 방대한 언어를 의미
1. Prompt + Query : ChatGPT라고 가정. 여기서 질문 입력
그런 질문들에 입력을 하면
3. Relevant Information for Enhanced Context : 이 과정과 Large Language Model을 거쳐서
5. Generated Text Response에서처럼 대답을 내놓는다
위의 사진과 같이 이루어지는 것도 있고 그냥 뉴럴 네트워크 모델을 통과해서 즉각적으로 대답을 내놓는 경우도 있다
우리가 질문을 하면 여기에 대한 대답을 LLM에서 내놓아야 한다
그 내놓은 과정을 어떻게 처리하는지 한번 보자
LLM의 언어 처리 과정
그림 1) Transformer 구조
그림1은 트랜스포머 구조이고 input과 output layer로 구성이 되어있다
input : 질문의 영역
input에서는 질문하는 거 GPT한테 무슨 질문을 한다면 그러한 것들이 다 input에 들어감
output: 대답을 생성하는
그것이 output단으로 넘어가서 output단에서는 대답을 생성
여기서 중요한 것이 그림2에 있는 Self-Attention이라는 것
그림 2) Self-Attention
기본적인 딥러닝 모델, 예를 들어서 이미지를 분류한다든지 글씨가 어떤 글자인지를 분류한다든지 이런 분류 모델은 데이터 자체에 특징만 뽑아내면 됐었다
분류 모델 = 데이터의 특징만 해당
그런데 언어 같은 경우는 결국에는 시간에 따라서 계속해서 내가 어떠한 소리를 말을 하고 있는 것이다
근데 그 말을 하고 있는 것이 인과 관계가 있다
예를 들어서
한국어 : 주어 다음에 목적어 다음에 동사
영어 : 주어 + 동사 + 목적어 이런 순으로 어순이라는 것이 있고
그리고 그 문장이 모여서 문단을 형성할 때 문장과 문장 사이에도 어떠한 관계가 있다
그러한 관계들을 Self-Attention이라는 구조에서 찾을 수 있다
같은 문장 한 문장 내에서 단어와 단어 사이의 연관 관계 혹은 상관관계를 보는 것이다
그래서 그림2에서 보듯이
왼쪽 단어들 사이에서 오른쪽에 위치 it이 가리키는 것이 animal이다
그래서 animal과 it, 이 두개의 연관성이 높다고 하고 animal이라는 걸 분석을 할 때 자기 문장에 있는 다른 단어인 it에 조금 더 가중치를 두는 것이다
이런 식으로 언어의 구조에 대한 이해, 어떻게 하면 조금 더 자연스럽게 말을 할 수 있는지를 컴퓨터가 학습을 하게 되는 것임
데이터 셋 같은 경우 인터넷에서 있는 방대한 양의 텍스트 데이터를 모은다고 했다
논문 같은 전문적인 것부터 그냥 일반적인 인터넷 댓글처럼 조금 문법이 틀릴 수도 있는 혹은 어순이 안 맞을 수도 있는 그런 데이터까지 다 포함
결국에는 언어에 대한 구조를 배울 뿐만 아니라 널리 알려진 지식까지도 다 알아서 습득을 할 수 있는 것임
그리고 지식들을 습득할 때 Word Embedding을 사용
Word Embedding이란?
결국에는 이런 단어와 단어들이 컴퓨터가 이해하려면 숫자로 변환이 되어야 한다
숫자로 변환을 할 때 조금 더 연관성이 높은 단어들은 유사한 숫자들끼리 묶이는 것임(연관성이 높은 단어를 그룹화)
위의 그림을 보면 수도와 국가가 짝지어져 있다
이것들을 다 하나의 숫자로 할당을 한다고 생각을 할 때
같은 국가와 도시의 묶음들은 같은 숫자로, 비슷한 거리에 있는 숫자들로 묶인다는 것임
이것이 Word Embedding의 원리
그림2처럼 Self-Attention을 활용한 이런 기본적인 언어 모델을 사용하면 비슷한 것들은 비슷한 숫자로 매핑이 된다는 것을 확인할 수 있다
그래서 이것이 Word Embedding의 특징이고 그래서 결국에는 어떤 특정한 태스크 즉 손글씨 분류 혹은 예측 같은 특정한 태스크를 목적으로 학습을 하는 것이 아니라 언어 모델 자체의 것을 학습하기 때문에 굉장히 일반화되어 있다
예를 들어서 분류 문제라든지 혹은 내가 어떤 텍스트를 넣었을 때 이 텍스트가 부정적인 감정을 담고 있는지 긍정적인 감정을 담고 있는지 그러한 특정한 문제를 풀고 싶을 때는 LLM을 갖고 와서 거기서 파인튜닝, 즉 우리들이 가지고 있는 데이터로 조금 더 학습을 시키는 것이다
LLM 자체가 이런 파인튜닝을 할 수 있도록 잘 설계가 되어 있다
ChatGPT 같은 경우도 사실은 GPT3 GPT4라는 사전 학습 모델에서 맞춤형으로 발전이 된 것임
그래서 이렇게 파인튜닝해서 사용할 수 있다는 것이다
LLM에서 해결해야 할 문제
LLM은 인터넷에 있는 방대한 양의 자료를 가져와서 학습을 한다
지식도 학습을 한다고 할 수 있는데 Hate speeches라고 혐오,증 발언 등에 노출 위험
그럼 이런 것들이 다 학습이 되고 사람들이 가짜 뉴스 생성, 갈등 유발 정도를 다 걸러내야 한다
이런 문제점들을 해결하는 것이 지금 LLM 모델에서 사람들이 연구하고 있는 분야들 중에 하나
또한 LLM은 gpt를 포함해서 굉장히 모델 자체가 크다(굉장히 무겁게 설계된 LLM)
결국에는 그 모델을 저장하고 관리하기 위해서 전기세가 많이 나감(유지비용 많이 든다)
그래서 이런 리소스 관리 같은 것도 LLM의 주요 과제
인터넷에는 영어 스페인어 이런 것들이 많고 한국어 같은 경우는 비교적 적다
그렇기 때문에 ChatGPT에도 한국어를 입력하면 생성 속도가 좀 느림
아직까지도 LLM 모델에서는 데이터가 적은 한국어는 비주류에 속하기 때문에 그런 비주류 언어에 대해서도 개발을 하려는 것이 많은 기업들과 연구소에서 하고 있는 것
'기업 프로젝트' 카테고리의 다른 글
| [AWS] 윈도우10에서 pem 파일 사용해 aws ec2 접속 (ssh) (0) | 2023.10.17 |
|---|---|
| 마이너 멘토링 10/12 (0) | 2023.10.12 |